

.png)

pdf文档怎么识别?PDF是一种可移植文档格式,是一种电子文件格式。与其他文件格式相比,它的特点是简洁性和可读性高。加上由于pdf文档安全性较高,无法直接对文档内的文字信息进行复制粘贴,为了解决这个困扰,今天我就给大家分享一个pdf文档文字识别的方法,这样就可以随时进行文字复制或二次编辑,有需要的小伙伴一起来看看吧!

软件推荐——万能文字识别
万能文字识别使用光学字符识别 (OCR) 技术,可以对扫描出的文档进行编辑和注释。它的PDF文档识别功能只需导入待识别的PDF文档.便可以扫描提取PDF文档中的图文信息,并保留一定的图文排版格式,输出为DOCX、TXT等格式的文本文档。此外,万能文字识别还支持图片转换、手写字识别以及各类票证识别,可以满足不同用户对图片文字识别的基本需求。
pdf文档识别在线操作步骤
第一步:选择功能
打开万能文字识别在线网站,在首页导航栏中选中【pdf文档识别】功能,点击进入在线识别界面。
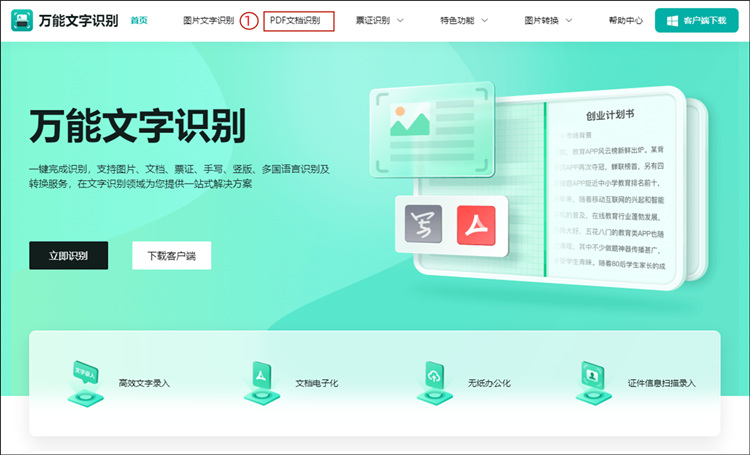
第二步:上传文档
进入在线识别页面后,点击【点击选择文件】按钮,在本地上传需要识别的pdf文件,仅支持 PDF 格式和支持2M以内大小的。
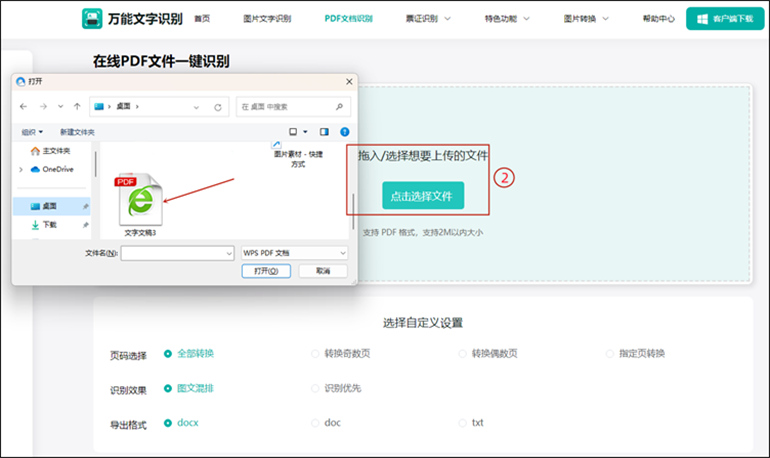
第三步:设置导出格式
上传完成后,设置要输出的文件格式(支持docx、doc和txt)、页码选择(全部转换、转换奇数页、转换偶数页和指定页转换)、识别效果(图文混排、识别优先)。设置完成后,点击【开始识别】按钮,网站就会进行识别操作。
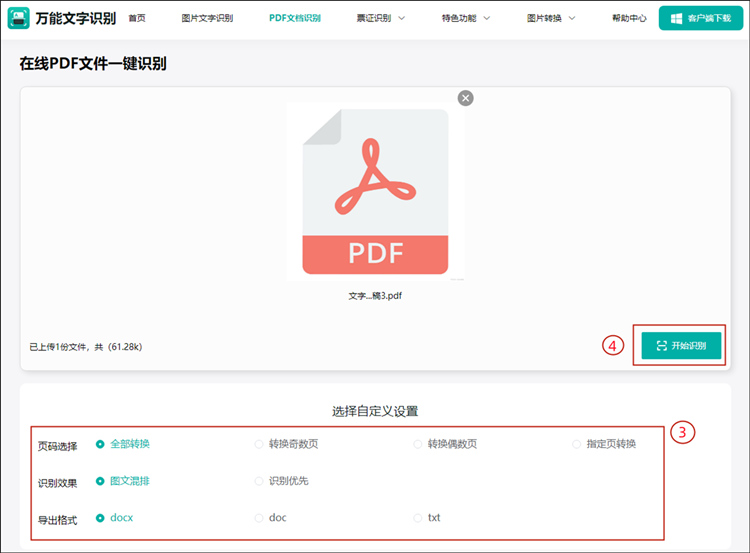
第四步:下载保存
等待几秒识别好后,原本的pdf文档就会以设置的导出格式呈现,点击【立即下载】按钮就可以将识别结果的文档保存到本地了。
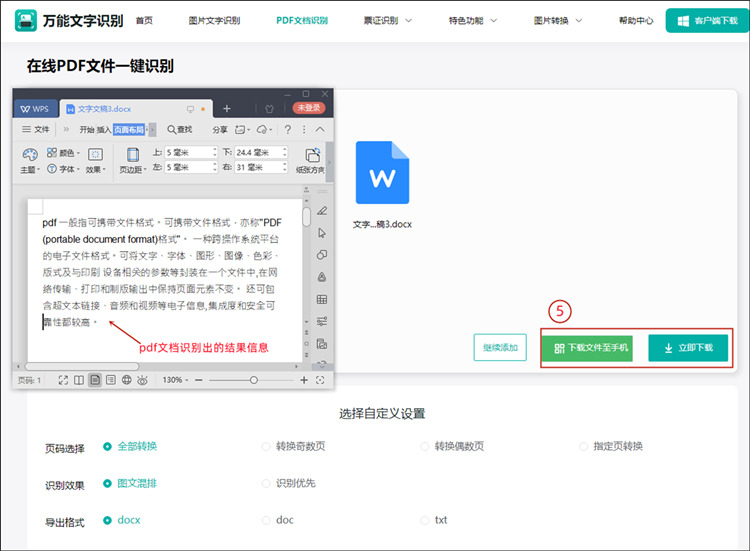
利用pdf文档识别工具,我们就能比较轻松地将pdf文档内的内容资料提取出来,并导出为自己需要的可编辑文档。那么关于“pdf文档怎么识别”的内容,本篇就分享到这里。希望小伙伴们看完后,都能顺利掌握识别方法。