

.png)

识别pdf图片中的文字怎么弄?在当今信息爆炸的时代,PDF文档已经成为我们获取和分享信息的重要载体。然而,很多时候我们会遇到需要从图片中提取文字的情况,尤其是当这些文字嵌入在PDF文件中的图片时。本文将分享三种PDF文档识别的方法,希望能够帮助大家轻松应对各种识别需求。

一、万能文字识别在线网站
万能文字识别在线网站是一种便捷的工具,用户只需在浏览器中进行操作,无需安装任何软件。它支持多种语言的文字识别,且识别准确率较高。对于需要频繁处理不同格式文档的用户来说,这是一个省时省力的好帮手。
使用步骤:
1.在网站中找到【PDF文档识别】功能,点击后上传需要识别的PDF文件。网站支持批量上传,大大提高了工作效率。
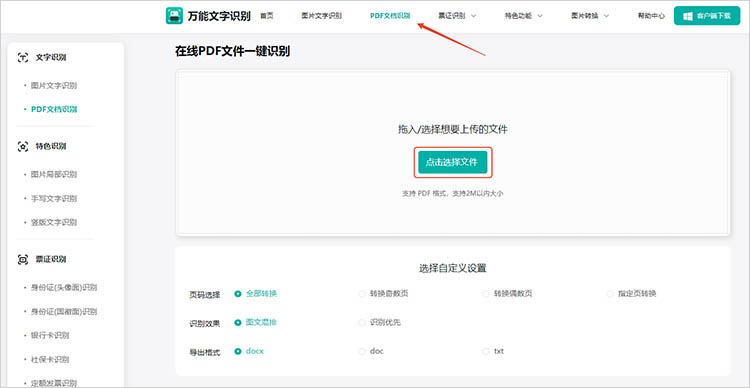
2.根据需求选择识别页码(如全部转换、指定页转换等)、识别效果(如图文混排、识别优先等)。
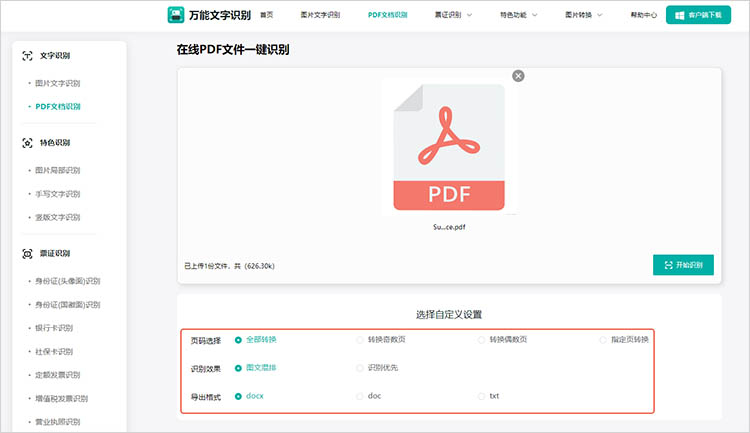
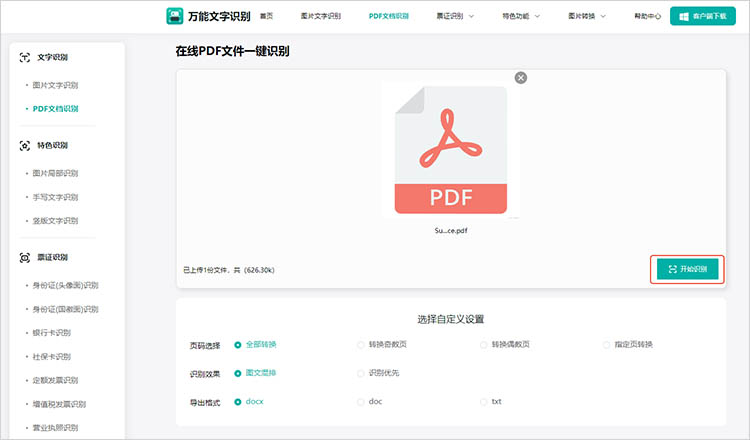
3.点击【开始识别】按钮,稍作等待即可看到识别结果。识别完成后,可以直接下载保存识别结果。
二、迅捷OCR文字识别软件
迅捷OCR文字识别软件是一款功能强大的识别工具,支持多种格式的文档识别。它的优势在于可以处理更为复杂的文件,同样支持批量识别,这大大提高了工作效率。此外,软件的识别精度和速度均非常优秀,适合需要频繁进行文本提取的用户。
使用步骤:
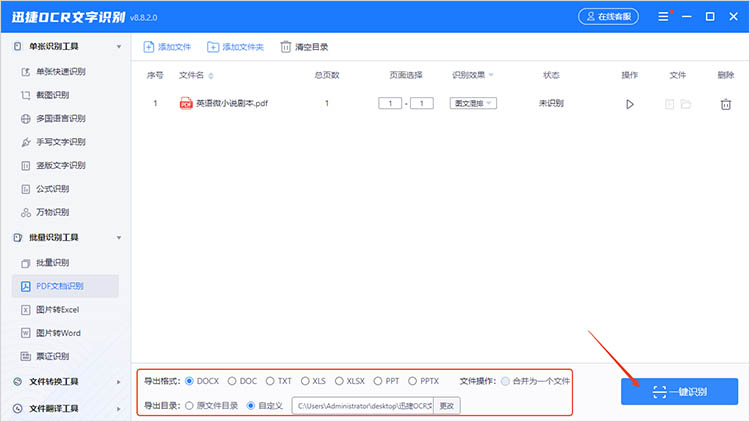
1.启动软件,在左侧的功能栏中找到【PDF文档识别】,并将需要识别的文件导入。
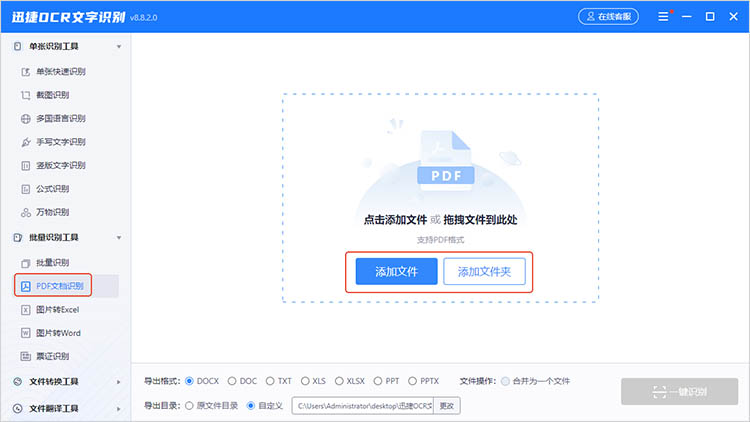
2.根据实际需求,在界面下方对识别参数进行调整,点击【一键识别】即可完成PDF识别。
三、迅捷PDF转换器在线网站
迅捷PDF转换器在线网站以其丰富的转换功能和灵活的在线操作,满足了用户在不同场景下的需求。无需下载安装,只需一个浏览器即可实现PDF与多种格式的相互转换,以及PDF图片文字的识别,非常适合临时需要处理PDF文件的用户。
使用步骤:
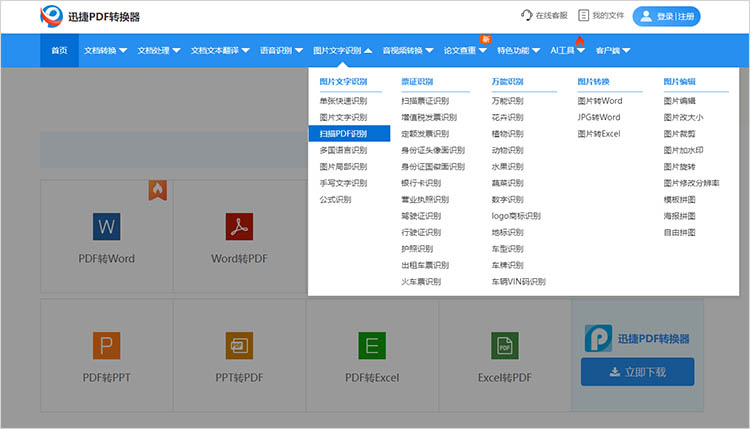
1.进入在线网站,在上方功能栏中找到【图片文字识别】-【扫描PDF识别】功能。
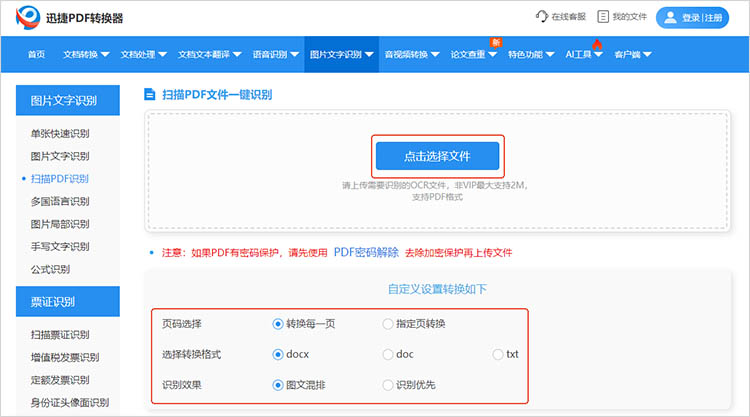
2.进入对应的功能页后,点击【选择文件】按钮上传PDF文件。上传完成后,勾选合适的自定义参数。
3.点击【开始识别】,网站将开始运行。识别后的文件,需要点击【立即下载】进行手动保存。

有关于“识别pdf图片中的文字怎么弄”的内容到这里就结束了。本文分享的这些工具凭借其便捷性和准确性,大大简化了我们从PDF图片中提取文字的过程。在未来的工作和生活中,当我们再次面对PDF图片文字识别的需求时,不妨尝试上述方法,让信息处理变得更加轻松。