

.png)

在日常工作和生活中,我们经常需要处理各种PDF文档。有些PDF文档中可能包含着重要的图文信息需要我们提取出来,由于PDF文档私密安全性较高,无法直接复制或编辑,如果手动输入这些文字,不仅费时费力还容易出错。今天我就分享一个pdf图片文字识别的方法,一起来看看吧!

一、选择合适的软件
利用专门的识别软件对PDF中的图文信息进行识别,是一个非常方便和高效的方式。目前市场上有很多种识别软件可供选择,这里推荐万能文字识别。
万能文字识别是一种能够自动识别图片中的文字信息并将其转化为可编辑的文本的工具,无需下载安装。它的PDF文档识别功能只需打开网站,导入待识别的PDF文档.便可以扫描提取出PDF文档中的图文信息,并保留一定的图文排版格式,输出为DOCX、TXT等格式的文本文档即可,非常实用。
二、具体操作步骤
1、打开软件,在首页的导航栏中选择【PDF文档识别】功能,点击进入在线识别页面。
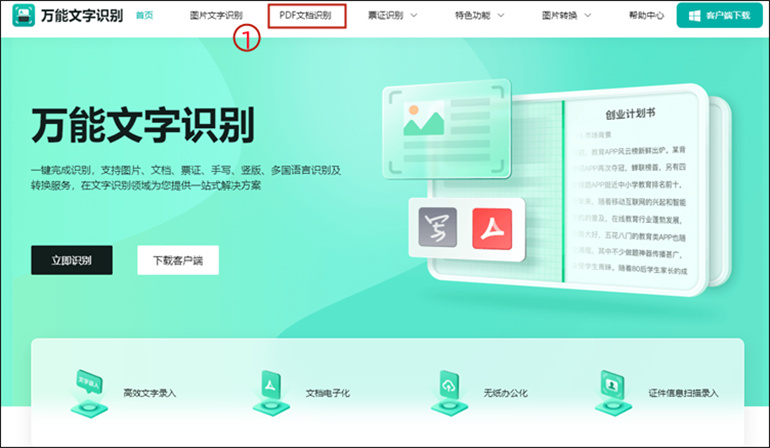
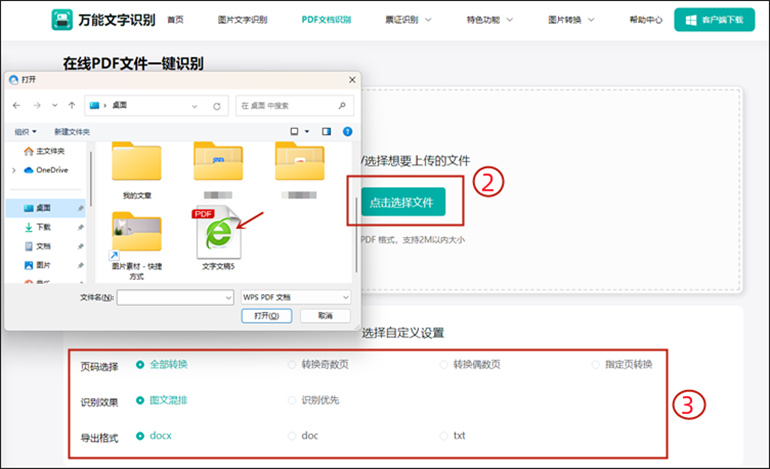
2、进入页面后,直接拖入或者点击【点击选择文件】按钮上传需要识别的pdf文件(仅支持pdf格式和2M以内大小);然后在下方的“选择自定义设置”中调整识别参数,包括页码选择、识别效果和导出格式三项。
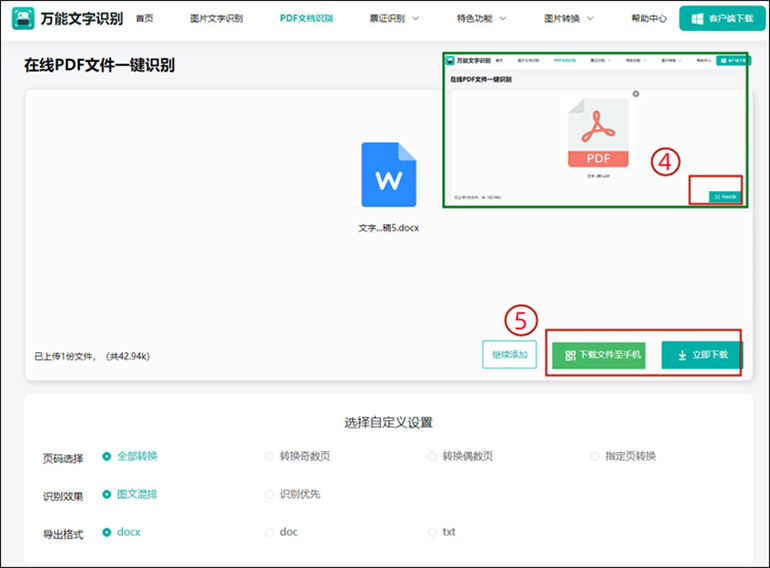
3、以上操作完成后,点击【开始识别】按钮,等待系统自动识别。识别结束后,点击【立即下载/下载文件至手机】将识别后的文件下载到本地即可。
总的来说,利用万能文字识别软件对PDF中的图文信息进行识别是一种非常便捷的方式,可以提高我们的工作效率和便利性。此外,它还支持对各种图片、各类票证及图片转换等其他功能,可以满足不同用户在不同的场景下使用。
关于如何进行”PDF图片文字识别“的操作方法,以上就是具体的介绍。在工作或日常生活中如果遇到了需要提取PDF文档中信息的情况,可以使用万能文字识别进行操作。